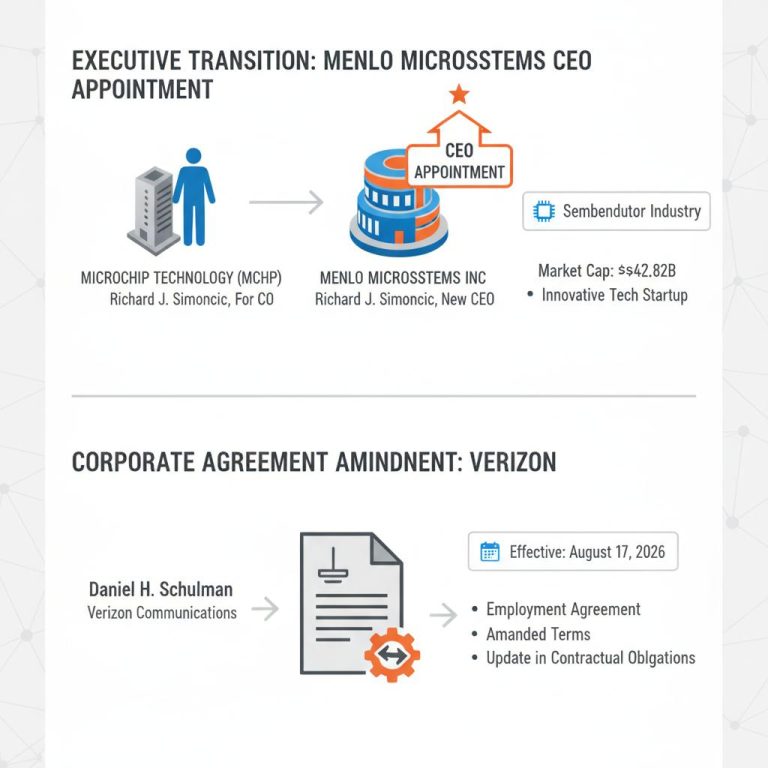
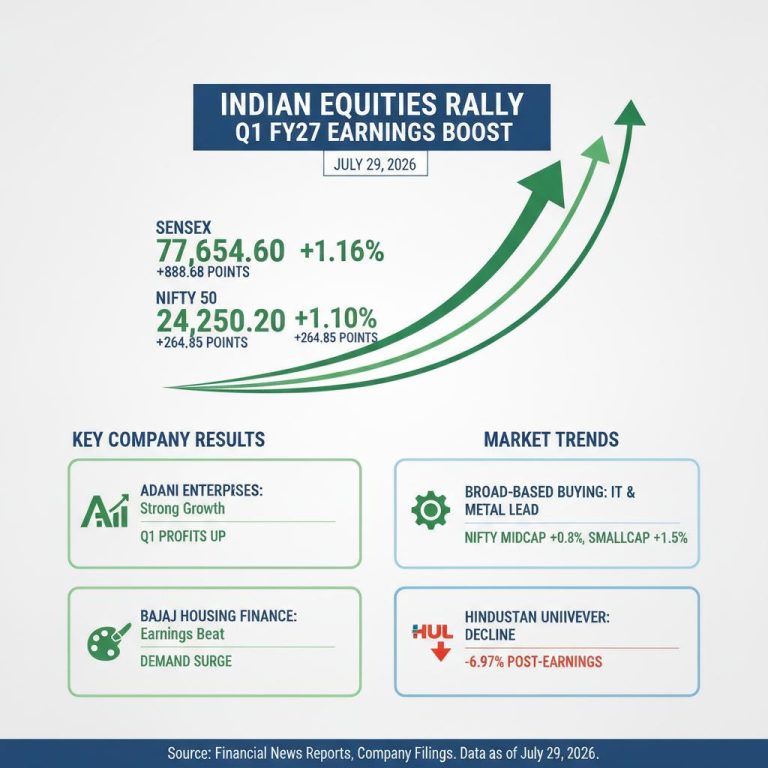
XDOF technicians manually sorting robot training data components in a vast industrial warehouse.
The race to develop advanced physical AI, capable of matching the achievements of Large Language Models (LLMs), faces a significant hurdle: the collection of high-quality training data. This process is often described as dirty, unglamorous work, far removed from the sophisticated algorithms and computational power typically associated with AI development.
However, companies like XDOF are stepping in to tackle this essential, albeit unappealing, task. According to a report from TechCrunch on June 17, 2026, XDOF is already being contracted by AI labs to gather the necessary data for training robots. This suggests a growing recognition within the industry that the success of physical AI hinges on solving this fundamental data problem.
While LLMs have demonstrated remarkable capabilities by learning from vast amounts of text and code, physical AI requires a different kind of data – data that reflects real-world interactions, object manipulation, and environmental understanding. This often involves manual, labor-intensive processes to capture the nuances that machines need to learn to operate effectively in the physical world.
The fact that AI labs are willing to pay for this service highlights its critical importance. It signals a strategic shift, where the focus is not just on algorithmic innovation but also on the foundational data infrastructure required for physical AI to advance. As the field progresses, companies that can efficiently and effectively provide this specialized data collection service, like XDOF, are likely to play a crucial role in shaping the future of robotics and AI.